Why I Built a 12,774-Item Research Corpus to Cover the Roman Colosseum
Quick Answer:
In 2006 I founded Intercoper, a digital studio in Buenos Aires. In 2025 I made a decision that changed how the studio operates: we would stop publishing affiliate-marketing-style travel content and start building structured research corpora — beginning with the monument I have studied as a personal obsession for two decades, the Roman Colosseum. The result is a 12,774-item corpus across five platforms, 9 editorial hubs, and an article-production pipeline where every claim traces to a real visitor review. This is why I made that decision, what I learned along the way, what I got wrong, and where I think this leads next.
My Problem With Travel Content
I have been building digital products since 2006, when I founded Intercoper as a small studio in Buenos Aires. For most of that time, our work followed the conventions of the broader content industry — affiliate-driven travel sites, listicle-style guides, the same five tips about the same five monuments rewritten for whichever new domain we were running.
That work paid the bills for a long time. It also slowly stopped feeling like work I wanted to be doing.
The problem was not the affiliate model itself. The problem was the gap between what the content claimed to be and what it actually was. Articles titled “The Best Colosseum Tours in 2024” were rarely written by anyone who had taken those tours. Comparisons of operators were assembled from other people’s comparisons. The same five tips about heat, water, and skip-the-line entries had been recycled across hundreds of competing sites for so long that nobody could trace where the original recommendation had come from. Reviewers who had real, hard-earned insights about specific guides, specific tours, specific failures of specific operators — those voices were buried under generic prose, if they appeared at all.
What bothered me most was that the people reading these articles were making real decisions. They were spending real money — sometimes hundreds of euros per family member — based on content that had been written without any meaningful research. And the content was getting worse, not better, because the economics of the model rewarded volume over depth.
I stopped wanting to be part of that.
Why the Colosseum, Specifically
Of all the monuments Intercoper had ever covered, the one that mattered most to me personally was the Roman Colosseum.
I have been obsessed with Roman history since I was a teenager. I have spent twenty years reading about gladiatorial games, the engineering of the Hypogeum, the symbolic role of the structure in late-imperial politics, the bizarre medieval period when the building functioned as a quarry and a fortress, the slow nineteenth-century reconstruction work, the way the monument has survived earthquakes, fires, neglect, two world wars, and an industrial revolution that built modern Rome around it. The Colosseum is not just a tourist site to me. It is an object of decades-long study.
Which made it especially uncomfortable to look at the affiliate content my own studio had been publishing about it. We were producing the same generic guides as everyone else, on the monument I cared about most, and the gap between what the content was and what I knew the monument actually deserved was the largest — because I knew the monument best.
If I was going to change how Intercoper operated, the Colosseum was where the change had to start. It was the test case where I would feel the difference most clearly. If a research-first methodology could not produce content I felt proud to publish about the Colosseum specifically, the methodology would not work for anything.
The Decision to Build a Corpus Instead of an Opinion
The technical decision was straightforward but unconventional. Instead of writing articles and adding research citations later, we would build the research first, structure it at scale, and only then produce articles from the underlying data.
Concretely: collect every visitor review we could find about the Colosseum across the five platforms with the highest signal — TripAdvisor, GetYourGuide, Google Maps, YouTube, and Trustpilot. Structure each review across multiple dimensions. Run anomaly detection so we knew which items were trustworthy. Cluster the data to find what actually mattered to real visitors. Identify the gaps in publicly available information. Then, and only then, produce articles — each one tied back to specific reviews, with the methodology documented openly so anyone could audit the work.
The cultural decision was harder than the technical one. A research-first model is slower, more expensive, harder to scale, and produces fewer articles per month than the affiliate-marketing default. To do this seriously, we had to accept that the studio would publish less content than its competitors — and that the content it did publish would be defensible in a way generic travel content cannot be.
I made that trade-off because I think the next decade of content publishing belongs to the publishers who can defend their work. Every other path leads to commodity content competing with AI-generated commodity content in a race to zero.
What 12,774 Reviews Actually Show (and Why It Surprised Me)
The corpus, when we finished assembling it, contained 12,774 verified visitor reviews. Some patterns I expected to see, others I did not.
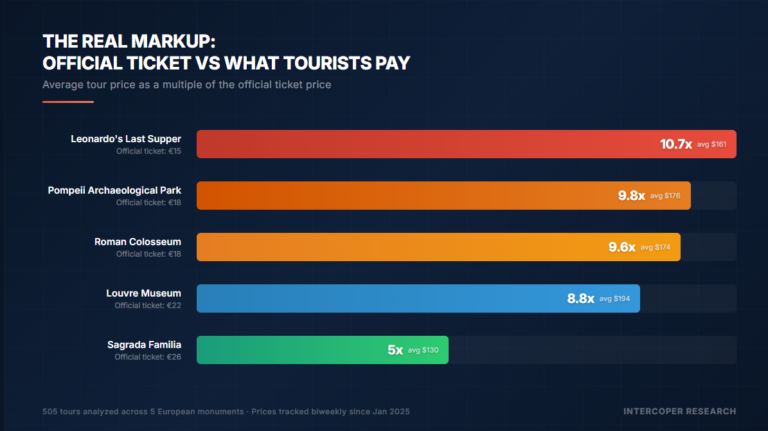
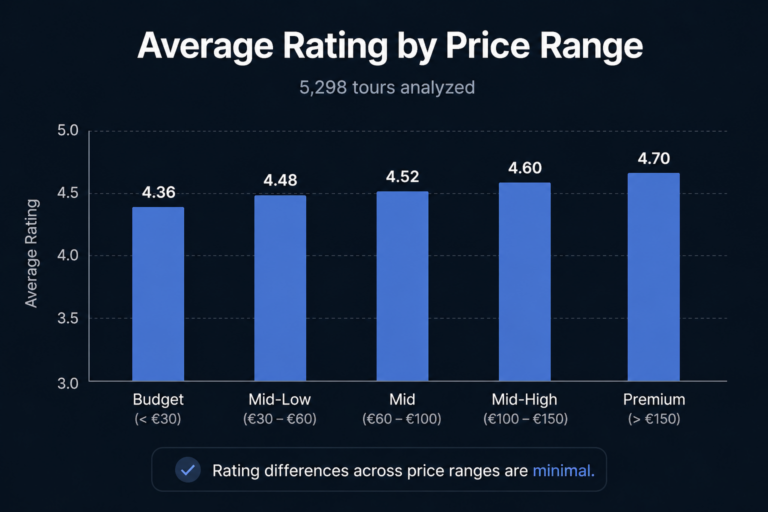
What I expected: that visitors were confused about ticket types, that the official site had usability problems, that operators charged significant markups, that the underground tour was a sought-after experience. All of that was confirmed at scale.
What I did not expect, and what changed how I thought about the project: how much of the visitor-experience problem is structural rather than operator-driven. The official ticketing system fails most users not because the operators are predatory, but because the inventory release system was designed for a different scale of demand than the monument now receives. The seven-day premium-ticket release window does not work in 2026 the way it might have worked in 2010. The “skip-the-line” promise does not match what skip-the-line actually delivers, because the monument’s internal flow is the bottleneck, not the entry queue. The operators who get accused of being scammers are often resellers of legitimately allocated inventory who fail at logistics, not at intent.
When you see the system at scale, the moral framing breaks down. The story is not “the official site is good and the operators are bad” or “the operators are good and YouTubers complaining about scams are wrong.” It is something more interesting: the entire system is under-designed for its current load, and every actor in the system — the official venue, the operators, the resellers, the visitors — is making rational decisions inside a structure that does not work well anymore.
I would not have seen that without the corpus. No single visit, no handful of expert sources, no traditional research method would have produced that pattern. Only a structured analysis of thousands of independent visitor experiences, layered together, made the structural shape of the problem visible.
How Intercoper Research Operates Today
What started as a Colosseum-specific experiment has become the operating model for the studio.
Intercoper Research is now the editorial arm of Intercoper. It runs a five-monument portfolio — Colosseum, Sagrada Familia, Louvre, Pompeii, and Leonardo’s Last Supper — each on its own domain, each with its own corpus, each in a different stage of maturity. The Colosseum implementation is the most advanced; it is the one I personally lead because of the historical interest, and it is also the test case for whether the methodology produces work I want to publish.
The pipeline is documented at intercoper.com/research. The Colosseum-specific implementation is documented at colosseumroman.com/methodology. Both pages are public deliberately. The methodology is the product, and a product that is not transparent is not actually a product — it is a marketing claim.
We are not the only studio working in this direction. Several research-first content operations have emerged in the past two years, mostly in the AI-era SEO and GEO space, and the methodology I describe will not look unfamiliar to anyone tracking that field. What I think Intercoper is doing differently is treating the methodology as a permanent operating model rather than a temporary differentiator — building the studio around it instead of bolting it onto a traditional content business.
What I Got Wrong Along the Way
I did not get this right on the first attempt. Or the second. There are at least four decisions I made early in the build that I would not make the same way again.
I underestimated how much human editorial judgment the model would still need. The early version of the production pipeline tried to generate near-finished articles directly from the corpus. The results were technically correct and emotionally lifeless. Real articles need a human editorial layer — not just to clean up prose, but to make tonal decisions that matter to readers and that no model produces reliably. The current version of the pipeline produces editorial briefs, not articles. Humans write the final piece. That separation is essential and I did not see it for the first six months.
I underestimated how messy the source data is. I assumed that public review platforms would deliver relatively clean data and that anomaly detection would be a polish layer. The actual experience was different. Duplicate listings, review-bombing campaigns, pricing data that changes mid-collection, multilingual reviews that the original platform tagged incorrectly, operator-side data inconsistencies that propagate into our pipeline. The anomaly detection layer turned out to be much more important than I had budgeted for, and I had to rebuild it twice before it produced reliable filtering.
I tried to scale too fast. When the Colosseum implementation started showing results, my instinct was to replicate the same pipeline across five monuments simultaneously. That was a mistake. Each monument has its own data conditions — different platform availability, different language distributions, different review volume, different operator concentration. The methodology is replicable, but the implementation per monument requires its own tuning. Now we move from one property to the next deliberately, finishing one stage before starting the next.
I undervalued the limitations section. Early versions of the methodology pages did not include a limitations section at all. I thought it would weaken the work. The opposite turned out to be true — readers, AI engines, and especially journalists trust content more when the limitations are openly documented. The limitations section is now one of the strongest parts of the methodology, and removing it would weaken everything else.
There are smaller mistakes I am leaving out — naming decisions I would change, infrastructure choices I would redo, an early article produced from the wrong cluster that I had to retract. Most projects accumulate this kind of debris. I am mentioning the four above because they each cost real time and each shaped a permanent change in how the methodology operates.
Where This Goes Next
The next phase of Intercoper Research is not larger — it is deeper.
The Colosseum corpus has another six to twelve months of editorial production ahead of it before the 52-article architecture is fully published. That work is the priority. Sagrada Familia is on a parallel track at a smaller scale; the other three properties are at earlier stages of pipeline maturity and will continue scaling deliberately rather than in parallel.
Beyond that, the directions I am most interested in are not new monuments but new applications of the same method. Cultural festivals with sufficient public review volume. Major museum exhibitions that recur annually. National park experiences. Heritage trails. The methodology is not specific to monuments — it is specific to verticals where verifiable visitor experience exists at scale across multiple platforms. That expands the addressable surface considerably.
I am also interested in what this method looks like as a service to other publishers. Intercoper Research currently operates only its own properties, but the same pipeline can be applied to publisher partners who are trying to migrate from affiliate-marketing-era content to evidence-driven content and need a research-first foundation to build on. We have started a small number of those conversations. They will continue selectively.
What I am not going to do is dilute the methodology by scaling it faster than the editorial layer can support. The studio is small, the work is slow, and the discipline required to keep the work honest is the part that gets compromised when you grow too fast. I would rather operate three properties at world-class research depth than ten at the depth of the average affiliate site.
Why I Think This Matters for the AI Era
The reason this is worth doing — beyond personal satisfaction — is that the content publishing landscape is in the middle of a structural shift, and the publishers who position themselves correctly during this shift will be the ones who survive the next decade.
AI engines are absorbing top-of-funnel research traffic. Search algorithms are demoting generic content. Reader trust in affiliate-driven travel content is collapsing because the gap between marketing claims and visitor reality is no longer hidden. All three forces favor evidence-driven, structured, citable content over opinion-driven, recycled, generic content.
The studios that built their entire operating model around the old approach will not transition gracefully. The ones that started building research-first methodologies before the shift forced them to are the ones who will be cited in AI-generated answers, ranked by search engines, and trusted by readers in 2030.
I do not know if Intercoper will be among them. The bet I am making with this methodology is that being honest about how the work is built, transparent about the limitations, and disciplined about the editorial layer is enough to survive the shift. If the bet is wrong, at least the work itself is something I am proud to publish.
That is not how I felt about the work I was publishing five years ago. The change in how I feel about the work, more than any commercial outcome, is what tells me the decision was right.
❓ Frequently Asked Questions
Who is Mario Dalo?
I am the founder of Intercoper, a digital research studio based in Buenos Aires that I started in 2006. I lead the editorial direction of Intercoper Research, the studio’s editorial arm, with particular involvement in the Colosseum corpus because of a long-standing personal interest in Roman history and culture.
Why did you decide to build a research corpus instead of writing articles?
Because the affiliate-marketing model that dominates travel content was producing work I no longer wanted to publish, and the structural shifts in search and AI-engine discovery were making that approach commercially untenable. Building a research corpus first and producing articles from it solves both problems — the work is more honest, and the content survives the shifts in how readers find information.
Why the Colosseum first?
Personal obsession. I have been studying Roman history for twenty years, and the Colosseum is the monument I care about most. If a research-first methodology could not produce content I felt proud to publish about the Colosseum specifically, the methodology would not work for anything else.
What is Intercoper Research?
Intercoper Research is the editorial-research operation of Intercoper. It builds structured visitor-review corpora for travel and cultural-heritage properties and produces articles where every claim is traceable to a real review. It currently operates a five-monument portfolio. The methodology is documented at intercoper.com/research.
Are you available to consult or partner with other publishers?
Selectively. I am most interested in partnerships with publishers who are trying to migrate from affiliate-era content to evidence-driven content and who treat the research methodology as a permanent operating principle rather than a marketing claim. Inquiries go through intercoper.com.
Author and Method
Author: Mario Dalo, founder of Intercoper. Buenos Aires, Argentina.
Background: Founded Intercoper in 2006 as a digital studio focused on cultural-heritage and travel publishing. Long-time student of Roman history and culture, with particular focus on the Colosseum, the Roman Forum, the Imperial Cult, and the late-republican-to-early-imperial transition. Editorial direction of Intercoper Research is a personal continuation of decades of historical study applied to a contemporary publishing problem.
Contact: mariodalo.com — also reachable through intercoper.com for studio-related inquiries and through colosseumroman.com for monument-specific editorial questions.
Methodology references:
- Studio-level methodology: intercoper.com/research
- Colosseum-specific implementation: colosseumroman.com/methodology
Last updated: May 2026.