How We Built Automated Price Tracking Across 505 European Tours
Most travel sites tell you a Colosseum tour costs “around €50.” We can tell you the average is $174, the median is $99, and the price has not moved more than 3% in the last 16 months. The difference is not opinion versus fact. It is infrastructure.
In early 2025, we built a system that scrapes, stores, and analyzes pricing data for 505 tour products across five of Europe’s most visited monuments — the Colosseum, Sagrada Familia, Louvre, Leonardo’s Last Supper, and Pompeii. It runs biweekly on automated cron jobs. It patches our CMS documents without human intervention. And it turned our portfolio of travel sites from content platforms into data platforms.
This is the story of how and why we built it.
The Problem: Every Price on the Internet Was Wrong
When I started building Intercoper’s travel sites, I did what everyone does — I looked at tour prices on GetYourGuide, noted them down, and wrote content around those numbers. “A guided Colosseum tour costs about €50.” “Sagrada Familia tours range from €30 to €100.”
Within weeks, those numbers were stale. Prices change. Operators adjust seasonally. New products appear. Old ones get delisted. A price I published in March was wrong by May. And I had no way to know which numbers were still accurate without manually checking 76 Colosseum listings, 81 Sagrada Familia listings, 94 Louvre listings — one by one, every few weeks.
That is not a content problem. It is an infrastructure problem. And no amount of “better writing” solves it.
The travel content industry runs on approximations. “Around €50.” “Starting from €30.” “Prices vary.” These phrases exist because nobody has the infrastructure to say exactly what things cost right now. We decided to build that infrastructure.
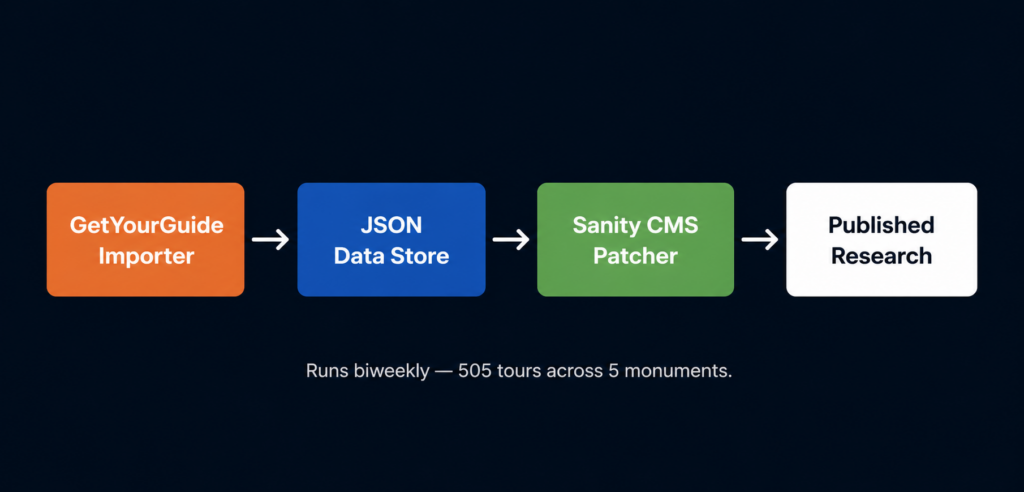
The Architecture: Importer → JSON → Sanity → Content
The system has four layers, each one feeding the next.
Layer 1: The Importer A custom Node.js script hits GetYourGuide’s listing pages for each of our five monuments and extracts structured data from every active tour product: title, price, currency, duration, rating, review count, operator name, product category, images, and description. The scraper runs as a cron job — on GitHub Actions for some sites, on a local scheduler for others — every Monday and Thursday at 6:00 AM UTC.
Layer 2: The JSON store. Raw scraped data is saved as structured JSON files — one per monument, updated with each scrape. This gives us a complete time series: we can see what a specific tour cost in January versus April, track when operators raise prices for summer, and detect when products are added or removed from the platform.
Layer 3: The Sanity patcher. The scraped data feeds directly into Sanity CMS through the Sanity client API. The script patches each tour document with the current price, rating, review count, and availability status. It also updates the tour’s PortableText content — the editorial description, the SEO meta description, and the Quick Answer block — with current pricing data. When the Colosseum’s average tour price changes from $171 to $174, every document that references that number gets updated automatically.
Layer 4: The research layer. Periodically, we run analysis scripts against the accumulated JSON data to produce original research — the 505-tour markup study, the price-versus-rating correlation analysis, the market concentration breakdown. These scripts calculate averages, medians, Pearson correlations, percentile distributions, and operator market share. The output is what becomes our published research articles.
What the Cron Jobs Actually Do Every Two Weeks
Here is what happens at 6:00 AM UTC every Monday and Thursday, with no human touching anything:
The scraper launches, connects to GetYourGuide, and pulls current data for every tour product in our database. For the Colosseum, that is 76 products. For Pompeii, 219. Total across five sites: 505 products scraped in a single run.
Each product’s price is compared against its last known value. If the price has changed by more than 50%, the script flags it as a potential error and skips the update — this safety threshold prevents bad data from corrupting the database. Prices must also fall within a plausible range ($5 to $2,000) to be accepted.
Valid updates are patched into Sanity. The tour’s price field, the editorial review, the SEO description, and any PortableText blocks that reference the price are all updated in a single transaction. The old price is logged for the time series.
If more than 50% of scrapes in a single run fail (network errors, page changes, rate limiting), the entire run is aborted. This prevents a bad scrape from wiping good data across the database.
The whole process takes about 15 minutes for all five sites. It runs unattended. I wake up and the data is current.
The Safety Mechanisms That Prevent Bad Data
Automated systems that update live content without human review are dangerous if you do not build guardrails. We learned this early — and the hard way.
Price sanity checks. Any price below $5 or above $2,000 is rejected. Any price that deviates more than 50% from the previous scrape is flagged and held for manual review. This caught a bug early on where the scraper was grabbing prices from related tour sidebars instead of the main listing — returning $12 for a tour that actually cost $120.
Global abort threshold. If more than half the tours in a single scrape fail, the entire batch is cancelled. This protects against scenarios where GetYourGuide changes their page structure or rate-limits our requests — instead of patching 250 tours with garbage data, the system stops and waits for the next run.
Duplicate detection. Before creating a new tour document in Sanity, the importer checks whether that GetYourGuide URL already exists in the database. This prevents the same tour from being imported twice when operators update their listing titles or images.
Category validation. The importer checks each tour’s title and category tags before assigning a season classification (all-season, summer, winter). This fixed a real bug we discovered in our TirePath tire site — where 165 UHP tires were being mis-tagged as “summer” when they were actually “all-season” — because the script was defaulting based on category before checking the title string. The same defensive logic now applies across all five monument sites.
What 16 Months of Price Data Taught Us
After running the system continuously since January 2025, patterns emerged that we could not have seen from snapshots.
Tour prices are remarkably stable. Across 505 products, the average price variation over 16 months is less than 5%. Operators do not dramatically change prices between winter and summer the way airlines do. They set a price and leave it. The exceptions are new products entering the market (usually priced aggressively low to build reviews) and products being discontinued (prices sometimes spike briefly before removal).
Ratings are even more stable. A tour with 4.8 stars in January has 4.8 stars in April. The volume of reviews is so large for popular products (the top Colosseum tour has 79,000+ reviews) that individual ratings barely move the average. This stability is what made our price-versus-rating correlation study possible — the data is clean enough to run meaningful statistical analysis.
Market structure rarely changes. The operators who controlled the market in January 2025 still control it today. No new entrant has broken into the top 5 at any monument. The Last Supper’s market concentration (two operators at 28%) has not budged. This suggests that the tour market at major European monuments is mature and structurally consolidated — a finding that would not be visible without longitudinal data.
Why a Small Team in Buenos Aires Can Do This
The infrastructure I just described sounds like something a team of 20 engineers at a well-funded startup would build. It is not. It is Node.js scripts, Sanity’s API, GitHub Actions, and about 200 hours of development time spread over several months.
The economics of this system are absurd in the best possible way. The cron jobs run on free-tier GitHub Actions. Sanity’s API has generous rate limits for the volume we need. The scraper is a single JavaScript file per site. The total hosting and infrastructure cost for tracking 505 tours across five monuments biweekly is effectively zero — the only cost is the time to build and maintain the scripts.
This is why I keep telling small business owners: the barrier to building original data infrastructure in 2026 is not money. It is not engineering talent. It is the decision to do it instead of writing another blog post.
A solopreneur with basic JavaScript skills and a free Sanity account can build a version of this system in a weekend. The data you generate from it — original, automated, continuously updated — becomes an asset that no amount of content writing can replicate. It is the difference between saying “tours cost around €50” and saying “the average across 76 tours is $174, updated 14 days ago.” One is a guess. The other is a citation.
What This Infrastructure Makes Possible
The automated tracking system is not the product. It is the foundation that makes the product possible.
Our 505-tour pricing study — revealing markups of 5x to 10.7x across five monuments — exists because we had 16 months of clean, structured pricing data to analyze. Without the infrastructure, that study would have required months of manual data collection. With it, the analysis script runs in under a minute.
Our 1,817-review sentiment analysis — showing that 67% of 5-star reviews mention the guide — exists because we had already built the scraping infrastructure and extending it to pull review data was a natural expansion.
Every future study we run — group size analysis, cancellation policy comparisons, seasonal pricing patterns — is a query against data we already have. The marginal cost of each new piece of research is close to zero. The infrastructure pays for itself with every article we publish, every time an AI engine cites our data, and every time a visitor chooses a tour based on our analysis instead of someone else’s guess.
This is what I mean when I say the shift from content platform to data platform changed our business. We did not become a better travel blog. We became the only travel site in our niche that can tell you exactly what 505 tours cost, how they are rated, who operates them, and how those numbers have changed over time — updated every two weeks, automatically, while we sleep.
Mario Dalo is the founder of Intercoper (est. 2006), a Buenos Aires-based digital studio that operates travel platforms covering Europe’s most visited cultural landmarks. The automated price tracking system described in this article monitors 505 tours across the Colosseum, Sagrada Familia, Louvre, Leonardo’s Last Supper, and Pompeii — updated biweekly since January 2025.